今天折腾了一天的ubuntu系统,先是18.04对于为这个电脑好多硬件不支持,声音,GPU都不行。决定升级20.04,20.04支持硬件驱动,但是从18.04到20.04升级太曲折了,升级完系统,wifi和声音都有问题,导致进不了系统,刚开始为切换到shell,禁止加载mod也是不行。
最后竟然发现进入恢复模式后,再切换到正常启动就能进入桌面了。恢复模式也提示了,桌面环境有的可能需要正常启动才能使用。为这个可能没正常启动,导致一些检测跳过了吧。后来装显卡驱动,升级了内核版本,然后突然间就好了。不知道为啥升级系统的版本的时候不给我直接升级内核版本。
哦对,不正常启动的时候,竟然cpu不太高,风扇呼呼转,不知道咋回事。正常了后也正常了。日志里的报错也没啥用,直到是wifi和声音mod的问题,但是没办法解决。
正常后的20.04的界面还挺好用,很流畅,也比之前好看多了。
开始界面调整外观风格没有变化,后来发现需要升级一下桌面,apt install ubuntu-desktop就可以了。
sudo lspci | grep -i nvidia
这个命令查看显卡信息的时候,因为没有显示,网上找了一个网站能通过id查询。
http://pci-ids.ucw.cz/mods/PC/10de?action=help?help=pci
url里的id是供应商id
再后来,帖子看多了,发现可以直接升级本地pci数据库。看来这电脑还真是硬件配置新啊。
sudo update-pciids
显卡驱动最后也没安装成功,懒得折腾了,暂时也用不到显卡的特殊功能,先这样吧。
Read more...
ansible这库终于能用了
最近又在写ansible相关的东西,因为得集成python项目,我开始都想之间命令方式调用ansible了。因为之前搞了好几个版本的ansible集成,每次都是大折腾一段时间,而且最早的时候,因为要集成或者解决问题,需要查看ansible源码,发现就是一坨。我好像不止一次跟别的同事说ansible是看过的最垃圾的开源代码。
最近又开始折腾了,虽然封装的接口还是不好用,但是看源码和修改给的example,最起码折腾起来轻松一点点了。源码也写的比之前好太多了。
playbook这玩意更坑,可能也是我写的不太多。
Read more...
mysql 主从模式搭建
面试面到这个问题,以前只知道dba大概用的啥工具,从来没想自己搞过,现在面试要求有这方面技能,回答的不是太好,我只知道通过binlog可以支持异步同步,具体不知道怎么做。配置软件的事还要问,也是醉了。
先搞最简单的模式,mysql自带的replication,这个应该就是最普通读写分离的主从模式了,可以一写多读。流量不高还是可以的,然后需要加一下主备,我看之前一般是通过keepalived去做的,多主这种一般使用percona的工具去做的,支持强一致的模式,这些都没搞过。我看mysql文档,mysql支持innodb集群,支持多主,这个文档还没看,后面再研究。还提到一个NDB Cluster。
我的mysql是安装的8.0.26,看官网不但支持普通的replication模式,通过binlog日志和同步的位置来同步,还支持global transaction identifiers (GTIDs) 的模式,这个replication模式不需要binlog了,看名字是事务相关。相关的文档还没看,只是先走了一下普通的模式。
首先,需要设置实例的server_id,这个需要集群里唯一,可在/etc/my.cnf里面加一条
[mysqld]
server-id=142
主从库都需要配置。
主库需要开启binlog,这个默认是开启的。从库视情况,如果需要作为别的从库的主库,也是必须要开启的。
从库需要配置一下relay-log,默认是按照主机名配置的,说是防止主机名变动,导致错误。
relay-log=/var/lib/mysql/re-relay-log
relay-log-index=/var/lib/mysql/re-relay-log.i
创建用于同步的专属用户
mysql> CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.example.com';
官网说,这个用户的密码是明文保存在从库中的,所以为了安全还是有必要创建一个的。
然后需要确定binlog同步的位置
先在主库加表的读锁,这样会阻塞写事务的提交。
mysql> FLUSH TABLES WITH READ LOCK;
新启动一个mysqlsession,执行SHOW MASTER STATUS,查看binary log的文件名和位置。文档说如果之前主库禁止了binlog,这个命令会返回空,在后边需要用到这俩值的时候,文件名为'',位置为4
释放锁的命令, UNLOCK TABLES;
最后一步是涉及在从库配置刚刚日志位置信息和主库信息。分两种情况,一种是新搭建的集群,另一种是主库本来有数据的情况。
我是刚搭建的环境,先用第一种。不同版本的mysql有两种方式,从8.0.23版本开始使用下面的语句
CHANGE REPLICATION SOURCE TO SOURCE_HOST='10.1.11.142', SOURCE_USER='repl', SOURCE_PASSWORD='123456', SOURCE_LOG_FILE='binlog.000001', SOURCE_LOG_POS=1012;
使用START REPLICA 启动同步
查看从库状态: show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
这两个状态为yes基本就没啥问题了
第二种情况,需要手动先把已有的数据从主库同步到从库中,其他一致。官方推荐使用mysqldump,特别是使用innodb引擎的时候。这种模式需要保持表锁不释放,不能退出session。
mysqldump 添加--master-data参数会包含CHANGE REPLICATION SOURCE 语句。然后导入到从库中。文档说有mysql插件可以方便做到数据迁移和从库配置。
又大概看了一些replication实现的文档,主实例有一个dump线程, SHOW PROCESSLIST里为Binlog Dump。从库两个线程,一个线程接受主库的dump线程的数据,写到单独日志文件,上边状态的Slave_IO_running为这个线程状态。一个线程应用前一个线程的relay日志的线程。多从的情况,主库会为每个从库配置一个dump线程。
复制的数据格式,有三种模式,一种基于语句的( statement-based replication),这种的在特定语句引擎会造成数据不一致。默认是基于行数据的( row-based logging),这种好像是复制更改内容的。还有一种是混合模式,是前两种的结合。
Read more...
haproxy编译安装
本来以为很快安装完了,没想到安装过程中缺少不少文件,就决定再记录一下吧。
看系统软件库里版本太低,我就想直接源码编译安装。官网下载了2.4.3的版本。
编译命令:make -j $(nproc) TARGET=linux-glibc USE_OPENSSL=1 USE_LUA=1 USE_PCRE=1 USE_SYSTEMD=1,这个是开启所有模式的编译方式,可看INSTALL文件配置
需要安装gcc:yum install gcc.x86_64
需要pcre:yum install pcre-devel.x86_64
需要openssl: yum install openssl.x86_64 openssl-devel.x86_64
需要安装lua,需要5.3版本以上,我从lua官网下载了5.4.3版本,可以直接make后,指定lua目录。make -j $(nproc) TARGET=linux-glibc USE_OPENSSL=1 USE_LUA=1 USE_PCRE=1 USE_SYSTEMD=1 LUA_INC=/opt/source/lua-5.4.3/src/ LUA_LIB=/opt/source/lua-5.4.3/src/
需要systemd-dev:yum install systemd-devel.x86_64
然后我现在记录才发现,就是参数指定的都需要额外安装的软件。
haproxy 配置文件
mkdir /etc/haproxy
cp examples/option-http_proxy.cfg /etc/haproxy/haproxy.cfg
配置systemd
cd admin/systemd/
make
会生成一个haproxy.service,我看就执行了替换bin目录
cp haproxy.service /usr/lib/systemd/system/
systemctl enable haproxy
直接start还是有问题,日志查看错误,需要改一下默认的配置文件和设置ulimit。
具体的详细配置还没看,只先瞟了一眼logging的配置。
Read more...
matplotlib画图依赖_tkinter的问题解决
最近接入他们大学的课题程序,很多都是用matplotlib画图,展示最终的精确度之类的。
然后我用pyenv+virtualenv安装那些程序的依赖,然后matplotlib需要_tkinter,这个还需要系统安装,虽然能装,但是挺费劲,还有种方式可能需要重新编译python,也是麻烦。网上搜索发现可以不使用的方法,每次装一次找一次,决定记录一下了。
直接import matplotlib.pyplot as plt
会报错ImportError: No module named _tkinter, please install the python-tk package
一般都是用plt.show()方式直接展示。我给改成plt.savefig()报错图片了。
网上找到的方法
在import之前加入两行:import matplotlib
matplotlib.use('agg')
然后就可以了。好像是选了matplotlib里gui别的显示方式,就不依赖_tkinter了
Read more...
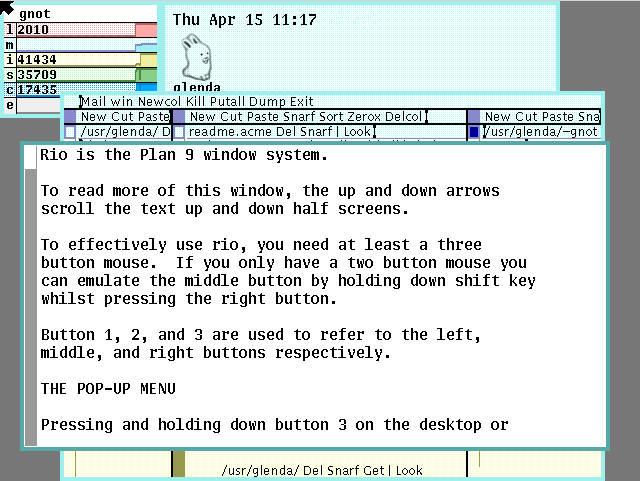
操作系统plan9安装
安装没啥坑,提示还挺好,照着官方文档安装,基本都是回车:http://9p.io/wiki/plan9/installation_instructions/
踩了三个坑,
一个是我选文件系统的时候选的fossil+venti ,硬盘选了2G,然后自动分区的时候可能把fossil分区的太少,复制文件的步骤太慢,而且各种报错,太慢了我感觉不堆,我又重启复制,报不同的错,最后才提示磁盘不足。我又重新开了个10g的硬盘,然后就可以了。
开始我还以为选择的镜像路线不对,然后发现可以ctrol+d退回到主菜单。
之后复制不到一分钟就复制完了,这个才是现代机器的速度嘛。然后重启后,输入用户名那里,提示的是none,我还以为进去创建文件,没想到的是需要输入默认用户名glenda,这个在安装文档里有,我后来报错才去看的文档。
放一张启动后的界面吧,感觉ui挺好看,就是还不成熟,vb中bug还挺多的。
我还看了点官方介绍,感觉备份那个思想现在Windows,mac应该都有,还有远程文件系统现在也都有,应该没啥新内容。待发掘
Read more...
刚知道的操作系统plan9
plan9可能有点古老了,看官网是80年代的产物,感觉那时候还没有操作系统垄断,dos可能也就刚出来,Windows还不知道在哪。今天想起来了,我又找了篇文章看了看plan9的介绍,反而激起了我对plan9的兴趣,感觉有些理念可以借鉴。被垄断后的思维就会狭隘,偏见,开开视野也是好的。
感觉好多古老的玩意还挺有意思的,比如老早之前知道,磁芯大战(core war or core wars),细胞自动机(cellular automata),《一种新科学》(A New Kind of Science)Stephen Wolfram。(这本书大体看了一下,有些思想我之前倒是想过,却没有这么深入细致的去研究)
记几个关键字,后边研究一下
装一下panl9操作系统,配置看一下那些特性,代码应该不会看。
Sam 和 Acme编辑器大体看看。
顺带知道一个操作系统Oberon,发现搜着看着东西越来越多了。
最近又看了篇文章,加深了对erlang的理解,之前还学过erlang语法,有时间再看看vm。
立了flag,不知道能不能看,发现要弄的东西不懂就难搞,不知道能不能坚持下来。下午有时间把plan9装一下。
Read more...
学习总结,最近心态又有点炸裂
学习的问题发现现在能很好的接受了,我开始认真学习数学。并且不去急功近利的学,还回头复习回忆,让学习效率最大化。
听了国外的机器学习基础课,国外讲的课还挺好,顺带看字幕学英语,听力也练了一点。因为讲课的内容相关性很高,所以词汇啥的很固定,学久了听这些内容就简单一点。
第二种机器学习的,相对篇应用的,也开始了。
每天背单词,收获也不少。
最近心态炸裂是工作上的事,全是坑,发现国企风格还是适应不了。现在打疫苗,同学群里的还是疫苗攻击啥的,他们都不打。不明白灭火了的疫苗还攻击啥,殊不知的是其他疫苗也有副作用,也没看不打。我跟我同学交流的最多,我发现他们很多事情就喜欢跟风,完全不会自己思考,而且总是想那个几件事。
所以独立思考的能力很重要。听网课,特别是你不清楚的领域的时候,确实能学到很多东西。我觉得之所以会选择这个模式,主要还是专业人事讲课的时候会特别系统,还有是总结后的东西,所以你能学到很多。虽然你自己也能思考,但是不够系统和细致(跨行导致总有你不知道的东西)。我买了一节便宜创业网课,加了群。里边的人听完课竟然跟跪舔一样一样的,让我十分不理解。我也觉得很值,讲的挺好,但我却没觉得有这么好。如果我站在这个角度,我也会思考这些东西,只是没有这些细致,还有全面。他们很多也是学习别人的书,还有借鉴自己经验的后的提炼。
最近还有一件还不错的事,就是开始做编辑器了。看看做一个开发进度的vlog,督促自己坚持下来吧。
Read more...
centos上搭建redmine,使用thin,nginx搭建
最近公司在找项目管理的软件,调研了一上午,然后给了几个方案。
一个是是否花钱,市面上的大部分都是花钱
第二个是是否本地部署,现在大部分不能本地部署,支持部署的也是花钱
之前用禅道,不支持多级子任务,不再使用,所以方案必须支持这点。
第三个是否能用破解版。
然后可以用破解版,我首先部署了jira,最后发现也不支持,插件好像也不行,官网也有人说了好几年了。
最后只能上redmine,这个系统勾起了我遥远的回忆,好像正式工作第一家就是用的这个系统,那时候我还改过ruby代码。这个我通过一个演示系统提前知道能多级。
下午又把这个redmine给部署了。这里简单总结一下,不是最优方案,但是内部使用基本没大问题。
使用的方案是,thin+nignx。thin类似于python中uwsgi等的那些。下边的方法是回忆着来的,不一定全,先记一波,以后部署再补充。
redmin安装查看官网教程足够。
安装完有测试启动方式bundle exec rails server webrick -e production,这个肯定不能用在正式环境,可能单线程,没验证
ruby的安装使用的rvm,类似Python里pyenv。
thin安装
gem install thin
thin install 能安装开机启动脚本,和etc下的目录。/etc/rc.d/thin
thin命令能生成配置文件,我直接复制的网上改的
cat /etc/thin/redmine.yml
pid: tmp/pids/thin.pid
wait: 30
timeout: 30
log: log/thin.log
max_conns: 1024
require: []
environment: production
max_persistent_conns: 512
servers: 4
daemonize: true
user: redmine
#socket: /tmp/thin.sock
address: 0.0.0.0
port: 8080
chdir: /data/redmine-4.1
这个配置刚开始怎么试sock都不行,后来端口也不行,我查了一下发现是selinux没关闭,关闭后再没试。让他们先通过thin起一个端口去验证了。
/etc/rc.d/thin start
/etc/rc.d/thin stop
这里会有问题
/usr/local/rvm/gems/ruby-2.6.6/gems/activesupport-5.2.4.5/lib/active_support/dependencies.rb:291:in `require': cannot load such file -- thin/connection (LoadError)
查了一下发现得在Gemfile文件里加上thin的引用,没写过ruby,看不懂,添加 gem "thin" 后 启动正常
nginx配置
这里配置基本复制的网上的,静态文件还是用的thin的,没走nginx,因为懒得去修改静态文件目录的权限了。
/etc/nginx/conf.d/redmine.conf
upstream thin_cluster {
# server unix:/tmp/thin.0.sock;
# server unix:/tmp/thin.1.sock;
# server unix:/tmp/thin.2.sock;
# server unix:/tmp/thin.3.sock;
server 127.0.0.1:8080;
server 127.0.0.1:8081;
server 127.0.0.1:8082;
server 127.0.0.1:8083;
}
server {
listen 10.10.12.240:3000;
server_name 10.10.12.240;
access_log /var/log/nginx/redmine-proxy-access;
error_log /var/log/nginx/redmine-proxy-error;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
client_max_body_size 100m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
# root /data/redmine-4.1/public;
proxy_redirect off;
location / {
# try_files $uri/index.html $uri.html $uri @cluster;
try_files $uri.html $uri @cluster;
}
location @cluster {
proxy_pass http://thin_cluster;
}
}
Read more...
ubuntu安装OpenGL ES 3.0开发环境
最近又心血来潮研究图形学去了,啃3d开发去了。n年前研究过,那时候心性不行,感觉太难了,搞了一半就放弃了。现在又准备重新研究了,目标定位到OpenGL es上了。
主要OpenGL ES支持手机平台,而且属于opengl的子集,没有历史包袱。虽然可能很多高级特效之类的不支持,但是应该也用不到,可能我学习的速度还赶不上硬件和opengl发展速度,考虑这些就考虑多了。从网上介绍来说es是可以在桌面上用的,但是网上搜了一下都需要模拟器。而我看的书是《opengl es 3.0 编程指南》这个书只是说libglesv2的lib版本,这个我就很疑惑。而且还推荐了很多桌面上的模拟器,用来跑示例,我这还想着桌面的也用es写,但感觉模拟器应该也能一起编译打包。
然后我搜了一下lib,发现libgles2已经安装了,搜的libgles,好多包安装过了。然后我看了一下头文件,GLES3/gl3.h也有。libegl也有安装。我就直接cmake了示例代码,然后运行成功了。
所以具体是这个包起作用,还是还有别的包,我也不太清楚,也懒得验证了。然后我就通过包信息里的官方网址,发现还是NVIDIA的github。里边头文件确实有gles3的,看了readme也没说支持3.0的es。大概率是支持了。
具体windows可能是需要模拟器了吧,或许也有显卡公司写的lib。
Read more...