我的老mac装个rlwrap及其费劲,懒得折腾了,找到一个common lisp的库,名字叫linedit。使用起来还挺好用,安装方法也比较简单:
(ql:quickload "linedit")
(linedit:install-repl :wrap-current t :eof-quits t)
Read more...
写了一个股票软件
花了点时间写了个股票分析软件,有的功能达到了预期效果,有的没达到效果。用ai编程写的,效率比我自己写高不少,感觉快个三四倍。
主要用的技术栈:
数据采集主要用的python+akshare,数据存储使用的clickhouse。主要抓取了十五年的日k线和行业数据。大概5400个股票数据,我只关注60和00的股票,不到3200家。
展示端做的桌面软件,使用c++,界面还是用的imgui,画线用的implot。直接读clickhouse数据库拿数据。本来想做成web的,想了想没啥必要,我也不会部署到服务器,而且还得多写个后端服务。数据大概1个G左右,我没有定制压缩和编码算法,使用的默认的。因为我之前参加过压缩算法的比赛,想了想这个东西还是得测,想当然没啥用。不是特别关注的点,所以懒得搞了。
功能上:
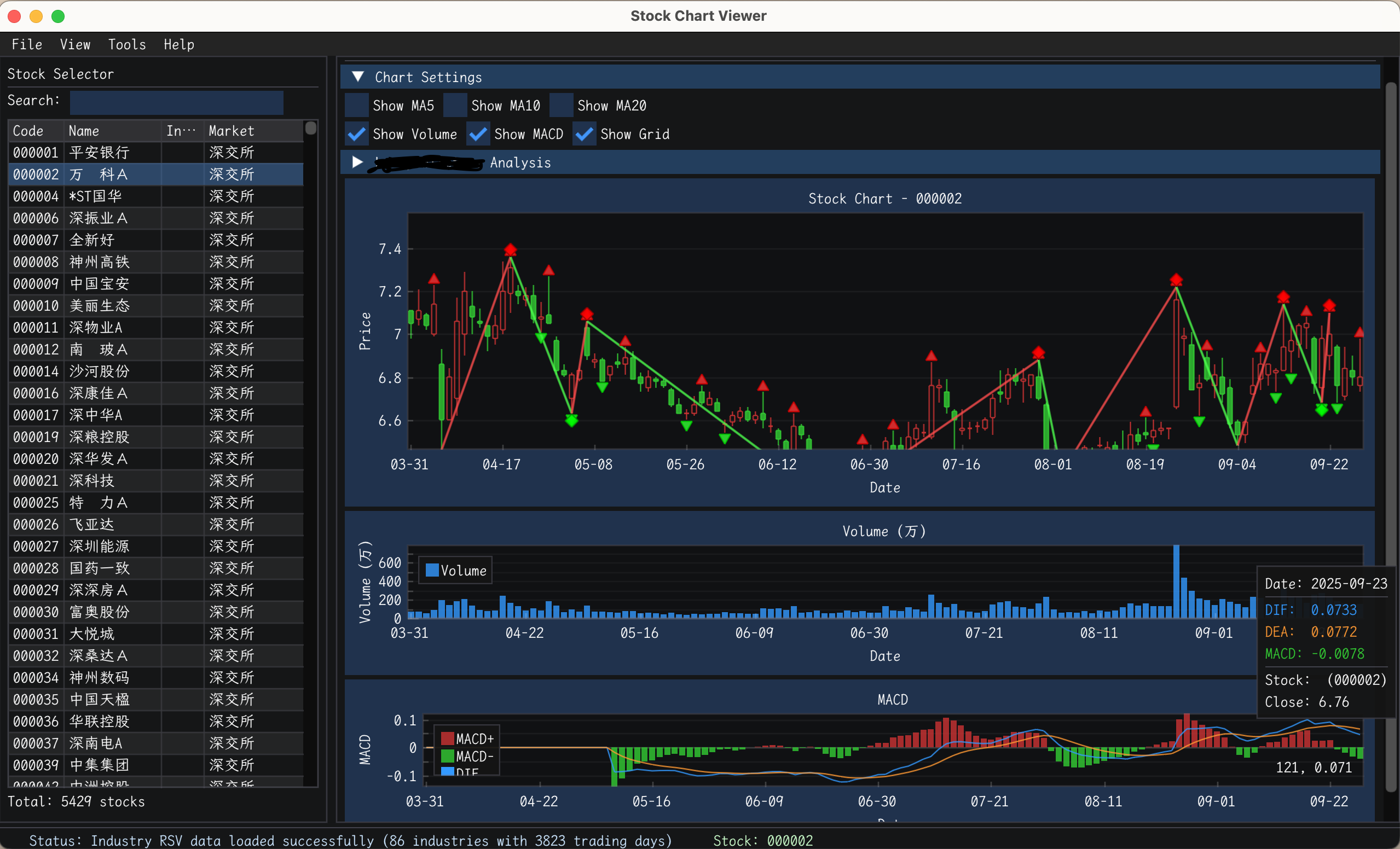
实现了k线图,均线(ai自动实现的),macd。k线图刚开始犹豫要不要加,后来想想,我过滤算法过滤出来,总不能再在别的软件上一个一个找,然后再分析,所以还是加上这个功能了。
macd自己搞的过滤算法,筛选股票,但是结果不尽人意,我还得接着改算法。
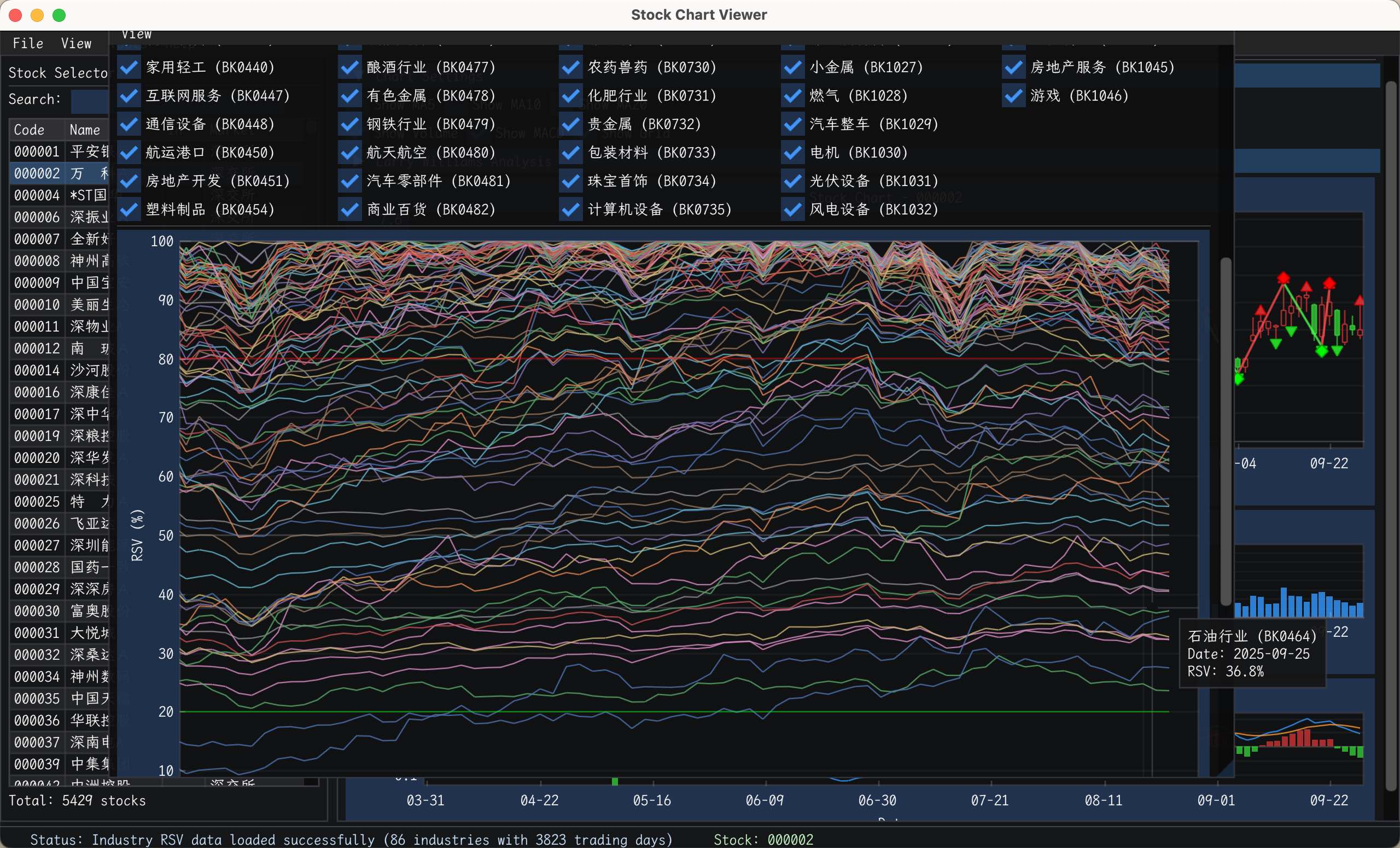
行业对比图,直观看那些行业属于启动了,或者历史顶部底部。这个功能比较满意.
实现的买卖点趋势图。买卖点我还没标注,主要看k线画趋势麻烦,有趋势了,买卖点一眼就看到了。这个功能比较好用,很满意。
想着实现的功能:
本来还想搞搞历史回测功能,写过滤算法或者交易算法,不回测直接上资金也不太行。算法优化暂时不搞了,这个后面再加吧。
界面:
Read more...
logstash导入json文件的时候,内容被截断的问题
这问题困扰我了接近三天时间。之所以困扰这么久,总结下来一个是自己太急了,本来是已经开发完的功能,然后文件一多就json解析不通过。然后最近工期忙,所以心态更急,越急越是慌不择路,反而没啥用。第二个就是测试周期长,只有在程序跑了二三十分钟的时候才会出问题。
我每分析一个文件,就产生一个md5命名的json文件,然后通过logstash导入到es当中,然后显出json文件,继续分析下一个文件。
问题的现象就是,logstash再导入一些文件后,会报json解析的错误,我打印结果显示读取的json不全。然后我看生成的json文件为全的,所以感觉是读和写之间的逻辑有问题,然后疯狂尝试,但是效果没有。我尝试了flush文件,现在想想确实没啥用,所以对问题进行冷静分析很重要。然后让我觉得是logstash的插件有bug,然后我查了github的提交记录和issue都没找到相关内容。然后又去看插件源码,比较复杂,心态也导致根本看不进去。最后又绕回文档,看参数相关的配置。
然后为看到logstash能根据inode识别出文件重命名的文档后,意识到我删除文件重新创建文件可能导致文件重用inode,然后我搜索了一下文档关键字。logstash确实提供了一个参数去按照过期时间删除文件读取的偏移记录。让我确定是因为我删除文件又创建新文件导致的inode重用,然后logstash根据之前记录的偏移地址去读取的文件,导致json不全,然后报错。
最终我使用truncate清空文件,然后再创建新文件去解决的问题。
Read more...
PWNABLE.KR第11题解题 coin1
这题纯编程题,二分法实现的,没啥意思。一直在调程序,最后发现超时了,还是在pwn服务器上很快跑完了。
Read more...
PWNABLE.KR第10题解题-bash的一个历史漏洞
这题没做出来,bash本来就不熟,去查了一些bash的语法,以为可以替换命令名称之类实现。
最终搜了一下答案,利用的bash之前的一个漏洞。这个漏洞之前新闻好像有印象,不太确定是不是同一个。
我看了一下漏洞介绍,使用bash -c执行命令的时候,虽然检查了环境变量传入的是一个函数,然后执行他,但是执行完函数后,并没有停止,会继续执行后面的代码。
这种题做起来有点难,不知道就很难做出来。
Read more...
PWNABLE.KR第9题解题
只能说我c写的还是少了,这题排除法做的。
看完代码先想的xor操作能不能推出密码,然后发现不行。然后根据题目提示,也没找到有优先级的问题。然后反着把代码看了一遍,发现有两处if语句优先级问题。
赋值运算算是最低优先级了,打开文件成功后,先进行比较运算为true,fd的值最终为true。导致从标准输入读取密码。
xor 1,前七位为0不变,最后一位取反。相当于找一个最后一位为0的字母,然后再输入下一个字母就可以了。
Read more...
PWNABLE.KR第8题解题 leg
这题又出的巧妙啊,本来我想动态调试一下,直接看寄存器值。但是还得准备环境,就放弃了。因为看代码比较简单,查了pc和lr盲猜了一波错了。然后就详细查了一波arm的pc指令。
先说key3的,这个盲猜的对了。lr就是回调返回地址,跟x86的一致。
key1考察pc指令,我查文章发现,arm指令流水线三级,包括取指(fetch)、译码(decode)、执行(execute)三级。
当前正在执行的指令获取pc值,pc其实指向的是fetch那条指令。相当于当前指令下面第二条指令的地址。
我看文章,这里arm还分ARM状态和Thumb状态,两种状态指令长度不一样。看来arm架构虽然指令长度是固定长度的,但是不同情况下不同的固定长度。这里就是key2里的.code16和.code32,指明指令长度。其实反汇编里有指令长度,所以这里也不需要关注,只要关注是往下数第二条指令就可以了。
这里key2一顿花里胡哨,其实还是pc+4的值。
最后求和提交就可以了。
我这里又多想了一点,二字节指令和四字节指令的区分方式问题,因为反汇编直接就显示出指令来了。我想了一下,可能在指令的机器码上还是有区分的。也懒得找资料认证了,arm汇编暂时也不想搞。
Read more...
PWNABLE.KR第七题解题 input2
这个题比较简单,主要是讲程序的数据输入方式有哪些。
涉及参数,环境变量,输入输出,文件,网络等方式。
Read more...
PWNABLE.KR第六题解题
这个题比较简单,刚开始我想错方向了。
其实考察c的rand函数需要一个seed。其实每次随机数都不变。gdb看一下随机值,然后得到异或值提交就可以了。
Read more...
PWNABLE.KR第五题解题
这个题耗费了我基本一天的时间,属于知识盲区题。
```
int passcode1;
scanf("%d", passcode1);
```
程序在调用scanf函数的时候,传的不是指针是一个int类型。编译会有warning,但是能通过编译。最终代码是以passcode1的值为地址进行数据存储。如果正常执行,因为passcode1的值不确定,所以很容易段异常退出。
在这调用login之前,调用了welcome,进行name[100]的输入。导致栈内存是共用的,所以可以通过设置name的值,来修改passcode1的值。
这里的分析都还好,再往下就不通了。因为共用栈刚好到name结束,而且二进制编译开启了函数调用的栈溢出检查,这就导致passcode2没有办法修改。只能说题出的精巧。
然后我从网上找了一下答案,然后再查了一些资料,基本就捋清楚了。
首先这里二进制未开启随机的内存地址空间的保护,导致每个指令地址固定。第二点,未开启got全保护,所以got可以写,导致可以修改动态库函数的调用地址,从而达到跳转到目的。
所以,继续往下的解题思路就是,在输入name的时候,修改passcode1的值为got函数的地址(通过查看plt段的内容)。这个函数取scanf后的一个函数,这样保证到达不了passcode2的scanf。这一步做完就可以保证,passcode1输入的时候不会段错误。然后在进行passcode1输入的时候,将最后的system调用的地址作为输入数据。因为指令地址固定,所以在这里行得通。
Read more...