我的老mac装个rlwrap及其费劲,懒得折腾了,找到一个common lisp的库,名字叫linedit。使用起来还挺好用,安装方法也比较简单:
(ql:quickload "linedit")
(linedit:install-repl :wrap-current t :eof-quits t)
Read more...
Archive for 算法-编程
写了一个股票软件
花了点时间写了个股票分析软件,有的功能达到了预期效果,有的没达到效果。用ai编程写的,效率比我自己写高不少,感觉快个三四倍。
主要用的技术栈:
数据采集主要用的python+akshare,数据存储使用的clickhouse。主要抓取了十五年的日k线和行业数据。大概5400个股票数据,我只关注60和00的股票,不到3200家。
展示端做的桌面软件,使用c++,界面还是用的imgui,画线用的implot。直接读clickhouse数据库拿数据。本来想做成web的,想了想没啥必要,我也不会部署到服务器,而且还得多写个后端服务。数据大概1个G左右,我没有定制压缩和编码算法,使用的默认的。因为我之前参加过压缩算法的比赛,想了想这个东西还是得测,想当然没啥用。不是特别关注的点,所以懒得搞了。
功能上:
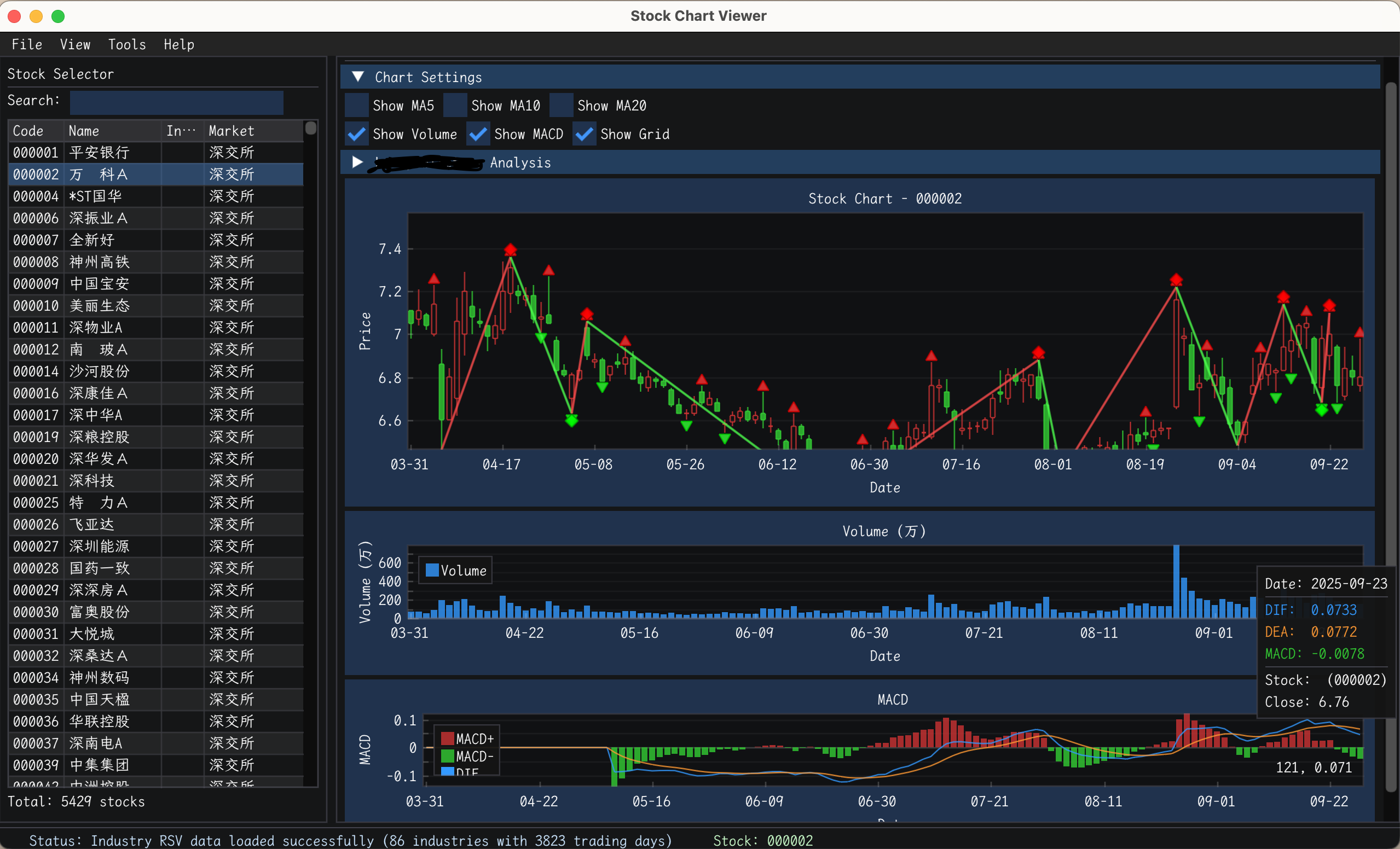
实现了k线图,均线(ai自动实现的),macd。k线图刚开始犹豫要不要加,后来想想,我过滤算法过滤出来,总不能再在别的软件上一个一个找,然后再分析,所以还是加上这个功能了。
macd自己搞的过滤算法,筛选股票,但是结果不尽人意,我还得接着改算法。
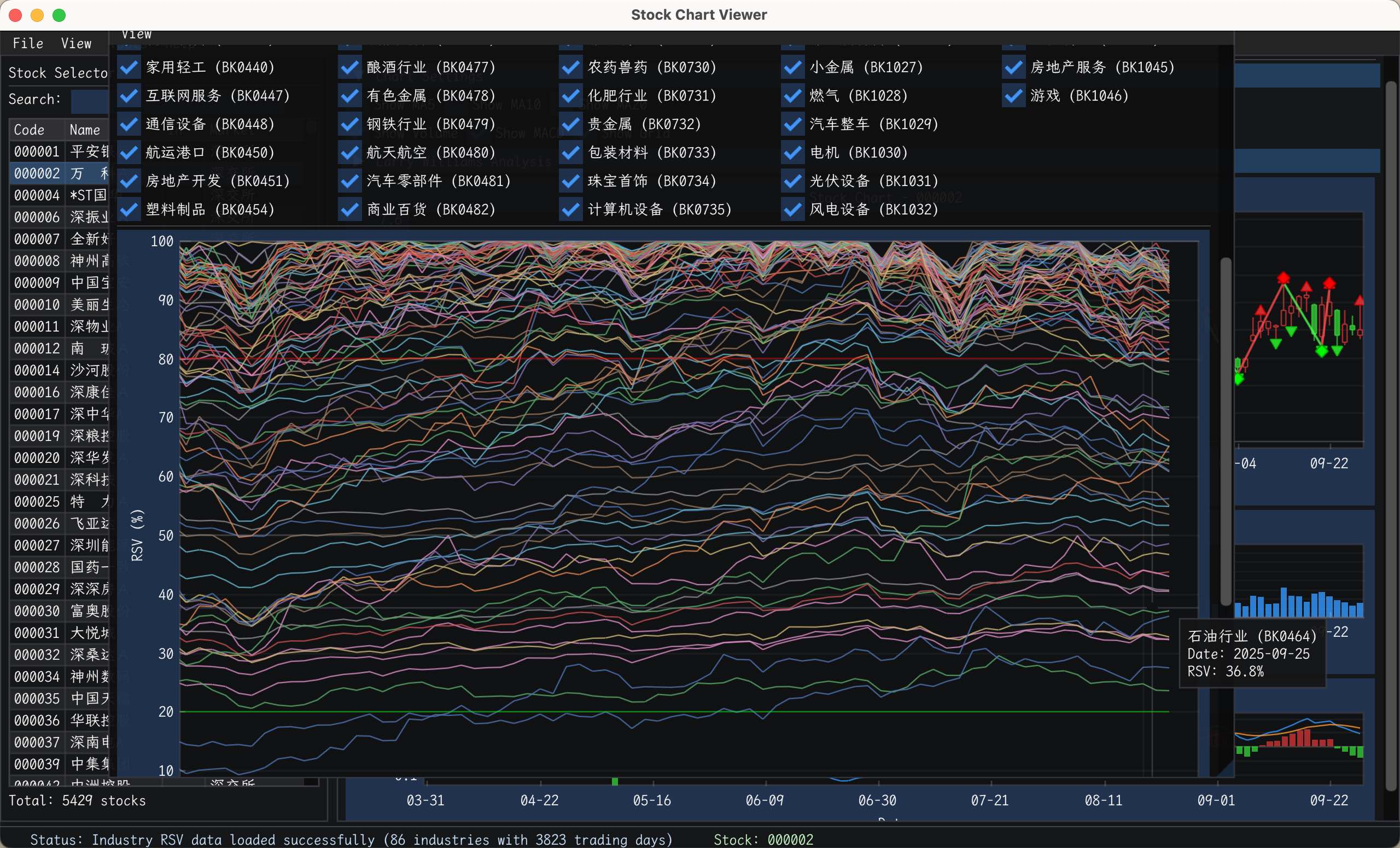
行业对比图,直观看那些行业属于启动了,或者历史顶部底部。这个功能比较满意.
实现的买卖点趋势图。买卖点我还没标注,主要看k线画趋势麻烦,有趋势了,买卖点一眼就看到了。这个功能比较好用,很满意。
想着实现的功能:
本来还想搞搞历史回测功能,写过滤算法或者交易算法,不回测直接上资金也不太行。算法优化暂时不搞了,这个后面再加吧。
界面:
Read more...
像素编辑器终于搞完了
我的像素编辑器马上就可以上线steam了,商店和应用的审核都过了,就等一到时间就发布了。
这个应用做的我还是挺头大的,因为基本没有做过比较大的成品的桌面工具,而且还是跨平台的。里面涉及很多技术问题之前都没有接触过,走了很多弯路,折腾消耗了很长的时间。不过现在回头看,倒也还好,正常的学习折腾阶段。可能目前还有bug。
软件功能属于基本的不能再基本的了,后面还好持续更新迭代。目前只实现了颜料板,工具栏,图层等基本功能。动画的帧没有实现,后期实现这个功能,需要捋一下帧跟图层的关系。这个现在还是脑子空白状态,说实话这种情况实现软件,在设计上不太合理,后面加帧的功能有可能需要大改代码结构。还有很多有意思的功能,比如笔刷,还有一些性能优化要做。还有一些基本的,比如快捷键映射,保存目录等一系列小功能。
技术上,其实做这个的初衷有一部分是为了实现游戏框架,因为我发现这东西跟游戏逻辑一模一样。游戏引擎完全通用。所以实现上我直接从底层写的引擎的相关逻辑,没用当前的一些游戏引擎。比如,我选择直接从opengl开始撸,说到opengl,这个我也断断续续学了好几次了,在这个编辑器场景下,我opengl的方案修改了三次方案,只为性能更好,现在也觉得有优化空间,还有几个优化的想法,但是得需要性能测试。
ui用了imgui,挺不错的一个库。完全可以深度定制,属于我的引擎的一部分了。完全可以在之后的游戏或者软件开发里继续用。说到ui,让我想起了这个软件编程语言的选择,本来开始想的是用纯c撸,但是后来发现c的库太少了。比如ui这里觉得imgui很好,最终觉得用他。就决定直接改c++的项目,但是里面代码还是一部分c一部分c++, c++基本只用到namespace和调库使用,还有一个std 库。std库提供的基本数据结构,能减少c的很多手撸代码的情况,算是特别方便了。
然后后来渐渐的,由于软件场景的需要,使用的c++的面向对象的功能越来越多。包括后来考虑跨平台的问题,升级到c++17的标准,看了很多cppreference的文档。觉得c++17甚至20提供了很多的新语法,不比现代语言差。慢慢的基本写的时候,都用c++的库,包括写法。尽量不写c,发现c++确实有很多优点(虽然现在很多c++高级功能还没用到)。让我再一次放下对语言的偏见。
觉得c++兼容的c的标准,属于成也萧何败萧何了。但是如果能尽量保持c++的风格,就也很好了。
其他的三方库用的很少,刚加入了psdlog作为文件日志的选择,刚开始封装了一个标准输出的日志代码,现在也用不上了,约等于白写。
编辑器支持psd文件的读写,使用的三方库,但是我也改了一些问题,当时挺头疼的。
还有一个很大的问题是国际化的问题,刚开始考虑复杂了,以为要通过操作系统的语言去切换软件的语言,后来steam官方说的是通过steam控制的。我刚开始选择了gettext这种老牌库,然后就坑了。在mac上,locale完全设置不了,但是自己启动时没问题的,通过steam启动,locale失效,设置也不生效。而且windows上没问题。为了解决这个问题,我本来想上icu4c这个库,因为这个库还能解决编码的问题,一举两得。但是感觉要改的地方有点多,最后手撸了个代码,自己实现了一个gettext。至于编码兼容的问题,目前适用大部分情况就可以了。后面再改的时候还是要用icu这个库。
说到跨平台和编码问题,确实c++这种语言,跨平台的问题太大了,包括代码和第三方库的编译,gettext我刚开始在windows上折腾,用的源码编译静态库,后来用的系统自带的。现在也用不上了。因为用camke管理的代码编译,windows下我用的mingw编译环境,这个也折腾了好几天。开始装了win7,想多兼容几个系统版本。库的链接一直不通过,我以为是版本问题,升级了版本,发现直接不能用了。后来升级win8.1发现一样的问题。然后才知道是库链接配置的问题。
这个软件,看似功能不多,但是细节做起来还是挺复杂的。除了上面这些不了解工具链或者系统环境等导致的问题,还有直接技术实现的盲区。我印象最深的而且很简单的场景是:刚开始实现完画布和画笔的时候,感觉很开心,那时候觉得这个软件至少实现百分之七八十的功能了。其实现在看来可能百分之十。然后我用画笔乱画的时候,发现一个问题,鼠标移动过快的时候,其实系统能检测到的根本不是连续的点,我的想法有点想当然了。这就涉及一个问题,线的补齐,而且还需要怎么样补齐的合理,这个是关键。刚开始是懵逼的,后来查了很多资料,发现针对问题的想法还是很重要的。
最后还得感慨一下,我这个steam坑位本来是要留给游戏的,现在变成像素编辑器了。倒是可以为以后的开发做技术积累和框架提前实现。只是我一直在想的问题,现在不准备从底层撸框架实现游戏了。现在看看使用JavaScript写了,这个引擎暂时在这个游戏上用不到了。只是因为JavaScript的跨平台能力,小程序之类的,webgl/webassembly这种的还是目前不是主流,肯定折腾的东西太多。学技术可以折腾底层,搞项目还是快速的框架比较好。
Read more...
suricata 源码阅读2-yaml配置文件加载
FinalizeRunMode,检查了一下daemon和运行的模式是否匹配,然后模式保存到全局变量run_mode中。
StartInternalRunMode,这个是判断是否是一些打印相关的模式,如果是这些模式,调用相关的方法,这些方法就不看了。比如列出模式,打印软件帮助等这类的模式。
GlobalsInitPreConfig,先调用TimeInit,初始化了一个当前时间的自旋锁current_time_spinlock,具体干啥的还不知道,调用tzset设置时区变量。之后调用SupportFastPatternForSigMatchTypes,初始化sm_fp_support_smlist_list,是个链表,默认保存了DETECT_SM_LIST_PMATCH,优先级为3,具体不知道这个是干啥的。之后调用SCThresholdConfGlobalInit,我看主要是初始化了解析Thresholding的正则表达式。
LoadYamlConfig,加载配置文件,调用ConfYamlLoadFile,这个里边主要利用了yaml库解析配置文件,没查这个库具体函数,函数名很容易知道是干啥的。保存了一下配置文件的目录,主要是调用ConfYamlParse,把配置读入ConfNode结构的树里边,有父节点,然后是个链表。所以也不单纯是个树。没太仔细看具体解析流程,单纯就是读到树里了。
typedef struct ConfNode_ {
char *name;
char *val;
int is_seq;
/**< Flag that sets this nodes value as final. */
int final;
struct ConfNode_ *parent;
TAILQ_HEAD(, ConfNode_) head;
TAILQ_ENTRY(ConfNode_) next;
} ConfNode;
ConfDump模式单纯就是把刚读如的链表树再打印一下。
查了一下“vlan.use-for-tracking”的值,这个参数看了一下配置文件介绍,基本用不到。
ConfGetBool获取配置中的bool值,先调用ConfGetValue获取值,里面通过ConfGetNode通过name找到node,key通过“.”进行分割,然后ConfNodeLookupChild查找当前等级的链表。看到这里发现,用c实现个json解析啥的好像也不太难啊。
SetupUserMode(&suricata);这个是设置非system模式的情况下,把日志和数据目录设置到当前目录,函数没跟进取,暂时不看了,这些模式不是看的重点。
SCLogLoadConfig应该是设置日志了,通过verbose设置等级,verbose通过参数有几个v来设置,等级为SC_LOG_NOTICE + verbose,看了一下SCLogLevel, 最高可以有5个v。获取logging.outputs的配置保存到outputs,SCLogAllocLogInitData初始化SCLogInitData,这个数据结构主要保存日志等级,格式,写到什么地方等信息。获取配置文件里"logging.default-log-level"配置的日志等级,然后跟参数里的比较,取等级最低的,保存到global_log_level。如果等级跟配置文件一致,使用配置文件的format。将outputs配置文件保存到变量,这些主要是日志的方式,console/file/syslog,没有细看,看了一下file的,这个用的多,调用SCLogInitFileOPIface,append模式打开文件,方式里面有个锁变量,注释说用来切割日志时候用的,然后调用OutputRegisterFileRotationFlag,把需要分割日志的这个flag都保存到output_file_rotation_flags里了,这个也是个链表。这里暂时有个疑问,我看flag初始化的时候没设置值,不知道后面会不会设置,还是我漏了。这里保存的是指针,可能不是漏了。日志等级还比较了outputs里的等级,取最低等级。然后调用SCLogInitLogModule,这个在之前调用过,之前可能是终端输出,现在可以配置文件了。
LogVersion,打印版本。
UtilCpuPrintSummary,打印cpu个数信息。
ParseInterfacesList,这里是看启动参数是否设置网口,如果设置会在配置里加一个xxx.live-interface的配置项,没设置就调用LiveBuildDeviceList,参数是模式,也是配置文件里的顶级名称,使用这个参数获取配置,如果interface为default,则忽略,这个是默认配置,其他情况调用LiveRegisterDeviceName,把接口插入队列,这个跟参数解析一致。所以看起来好像启动参数不加网口也可以啊。
Read more...
suricata 源码阅读1-初始化操作
SuricataMain是入口函数,先调用SCInstanceInit,把SCInstance变量数据清0,不知道为啥以及memset0了,还要变量名再置0一次。SCInstance就是suricata进程相关的一些变量,其中一个有意思的事是还保存了执行命令的文件名,看这个感觉可能直接改二进制的名也没问题的。run_mode设置为RUNMODE_UNKNOWN。
之后调用InitGlobal,主要设置suricata_context变量,这个变量在rust-context.h文件定义,全是操作函数,具体赋值的函数还没有看,这个先过了。
在InitGlobal里调用rs_init,这个看了一下好像是给rust调用用的,sc赋值给rust里的sc,这样在rust里可能就能试用context的函数了,我看在core.rs中都是contxt里的函数声明。具体c和rust怎么交互的,我还需要再看看。粗略看了一下,协议判断好像都在rust里写的。
然后初始化engine_stage为0,这个变量为原子变量,原子操作都定义在util-atomic.h,没细看怎么实现的,先知道干啥的吧。这个变量注释说的是表明引擎是在初始化还是在处理数据包了,总共包括三个状态SURICATA_INIT,SURICATA_RUNTIME and SURICATA_FINALIZE。
SCLogInitLogModule,初始化日志模块。没细看,参数传的NULL,使用默认日志系统。info等级打印到console,可以设置正则过滤,这几个设置项都可以通过环境变量设置。
之后ParseSizeInit,初始化了一个正则匹配器parse_regex,这个正则表达式不知道干啥的,看后面好像是把字符串“10kB,10GB”类似的转换成具体的大小数据,可能是配置文件之类的解析,先过了。
之后RunModeRegisterRunModes,跟函数名一个意思,注册的模块还没看。看配置文件就知道四五种,没想到还挺多。注册到数组runmodes。找了几个看看,发现就是list-runmodes里的模式,把对应的模式和具体模式的方法进行注册。每种模式都是调用RunModeRegisterNewRunMode注册到runmodes数组保存。RunModeFunc是对应的模式函数,这个先没看,等用到再看
之后ConfInit,初始化配置模块,ConfNode是一个列表,里面是kv键值对。起始就是初始化一个链表。
到这InitGlobal就结束了。
ParseCommandLine解析命令行参数,列出了所有参数,pfring或pfring-int参数启动pfring,设置run_mode为RUNMODE_PFRING, 如果后面跟参数,设置pcap_dev,这个应该是网口名了。LiveRegisterDeviceName就是把网口插入到一个链表里,相当于注册了。变量名pre_live_devices。capture-plugin还能设置插件名,这个模式RUNMODE_PLUGIN,可能dpdk得插件实现。netmap参数只能设置一次,看来只能在一个网口使用,而且还不能多个模式。
suricata --list-app-layer-protos 列出七层协议
suricata --list-runmodes 列出模式
list-keywords 关键字
-l设置日志目录
-i和af-packet都走af-packet,-i如果支持,默认也走af-packet。
这些参数在help里都有,暂时不看了,到时候回来看具体设置了什么参数,因为我看的代码比较新,之前版本的还有没有的参数。
Read more...
matplotlib画图依赖_tkinter的问题解决
最近接入他们大学的课题程序,很多都是用matplotlib画图,展示最终的精确度之类的。
然后我用pyenv+virtualenv安装那些程序的依赖,然后matplotlib需要_tkinter,这个还需要系统安装,虽然能装,但是挺费劲,还有种方式可能需要重新编译python,也是麻烦。网上搜索发现可以不使用的方法,每次装一次找一次,决定记录一下了。
直接import matplotlib.pyplot as plt
会报错ImportError: No module named _tkinter, please install the python-tk package
一般都是用plt.show()方式直接展示。我给改成plt.savefig()报错图片了。
网上找到的方法
在import之前加入两行:import matplotlib
matplotlib.use('agg')
然后就可以了。好像是选了matplotlib里gui别的显示方式,就不依赖_tkinter了
Read more...
ubuntu安装OpenGL ES 3.0开发环境
最近又心血来潮研究图形学去了,啃3d开发去了。n年前研究过,那时候心性不行,感觉太难了,搞了一半就放弃了。现在又准备重新研究了,目标定位到OpenGL es上了。
主要OpenGL ES支持手机平台,而且属于opengl的子集,没有历史包袱。虽然可能很多高级特效之类的不支持,但是应该也用不到,可能我学习的速度还赶不上硬件和opengl发展速度,考虑这些就考虑多了。从网上介绍来说es是可以在桌面上用的,但是网上搜了一下都需要模拟器。而我看的书是《opengl es 3.0 编程指南》这个书只是说libglesv2的lib版本,这个我就很疑惑。而且还推荐了很多桌面上的模拟器,用来跑示例,我这还想着桌面的也用es写,但感觉模拟器应该也能一起编译打包。
然后我搜了一下lib,发现libgles2已经安装了,搜的libgles,好多包安装过了。然后我看了一下头文件,GLES3/gl3.h也有。libegl也有安装。我就直接cmake了示例代码,然后运行成功了。
所以具体是这个包起作用,还是还有别的包,我也不太清楚,也懒得验证了。然后我就通过包信息里的官方网址,发现还是NVIDIA的github。里边头文件确实有gles3的,看了readme也没说支持3.0的es。大概率是支持了。
具体windows可能是需要模拟器了吧,或许也有显卡公司写的lib。
Read more...
python使用matplotlib作图横坐标日期显示不全的问题
临时看个问题,对matplotlib没有了解,基本纯网上搜了搜。暂时先记录一下。
是使用 pandas读了一个excel表,然后加了index字段,是个日期,数据保存在变量df里,可以直接调用df.plot()进行画图,我是有点震惊的。这是因为这几个库联用的多嘛。画出来的图横坐标日期不能全显示,然后想全显示出来。
第一反应就是日期太长了,然后找可以调整角度的函数,用xticks修改角度,不好用。然后发现xticks可以指定横坐标显示位置,显示映射啥的。
x=np.arange(0,12,1)生成一个选择的映射,label传入全部十二个日期。然后就显示全面了。plt.xticks(x, mon, rotation=90)
xticks参数还可以指定Text类型的参数,进行文本样式的设置。
最近让搞R语言,在看R语言画图的功能。因为看我对python的matplotlib,numpy,pandas这些库都没经验,领导之前会用R,就让我直接写R了。感觉搞这些工具,但不会统计的东西,搞起来总感觉是在隔靴子挠痒。
Read more...
使用Rserve实现java调用R程序
看网上教程,最后选择了这种rpc调用的方式,这种方式可以提前启动R虚拟机,R程序造成的崩溃不会影响到java程序。另一种方式是JRI,全名是Java/R Interface
第一步R安装Rserve,这里有点问题就是最好root权限安装,我看文档这种方式需要源码安装,并且有$R_HOME/bin权限。所以直接root启动r然后安装了,install.packages("Rserve")。这里试了一下R INSTALL 好像只能安装本地的包。最后决定安装官网的最新版本,目前还没在CRAN中。install.packages("Rserve",,"http://rforge.net")
第二步启动R server,命令行执行 R CMD Rserve,这个就是上边说的daemon模式,文档说只支持unix系统,windows还不行。默认启动端口6311.看参数好像只能指定端口,不支持指定IP。看文档只能通过配置文件去指定是否允许远程访问。写一行remote enable就行了,我没在默认/etc/Rserv.conf 改,直接参数指定的文件。
第三步java客户端连接,这里需要两个jar包,官方网站能下载,看版本有点老,安装包也带。目录在 /home/xx/R/x86_64-pc-linux-gnu-library/4.0/Rserve/java/ 包的安装目录下。然后javac -classpath ./REngine.jar:./Rserve.jar:. test.java,测试运行一下没啥问题。数据类型的转换问题还需要详细研究一下。
Read more...
使用python压缩扫描pdf文件,压缩率0.1
代码基本网上搜的,没啥贴的,写一下思路,有需要的自己网上搜就行了。主要是自己看的电子书是扫描版的pdf,里边全是图片,超级大,好几百M。之前找了一圈,靠谱软件需要收费,不靠谱个人软件只能windwos下用。于是自己搞吧,发现也不太难。
第一步是把pdf提取图片
用到pymupdf库,这个是封装的c的接口,感觉写个pdf软件也不难啊,都有开源库,不知道为啥他们还收费。我提取图片发现,好多水印图片是直接用pdf编辑软件加上的,导致水印可以直接从提取的图片里边删掉,这个挺好。
第二步,把图片二值化
这里用到opencv,用到cv2.threshold。这个阈值不太好设置,可以使用cv2.THRESH_OTSU,提取一个分析值,但是这个不是最优的,有的书是半彩页的,书边会有浅色的背景之类,或者重点颜色等。这个有分析建议值之后,还需要自己试一下哪个值比较好。
第三部,把图片生成新pdf
这个还是用pymupdf库,基本都差不多。
没想到的是压缩率还挺低,一百多MB的pdf能压缩成十多兆。可能也是之前的pdf质量比较高吧。但是我看了一下压缩后的,清晰度一点不减少。有背景色的地方,选择阈值合适,背景色也都过滤掉了,文字不受影响。
Read more...